 Removing duplicate Records in TSQL is likely to be a unique situation every time but there are enough consistent characteristics to the task that we can standardize some of it. I certainly would not want a one-button-click solution because that would have too narrow a view of what a duplicate is. Defining a duplicate is something for administrators to do because they know their data better than anyone else. Ask a director, a manager and a user what a duplicate record is and you will likely get three different answers. Sure, each will tell you when records appear as duplicates in reports and such, but the combination of fields that make up a duplicate is something that should be examined closely in every situation. Other than the standard of backing up a table, identifying the fields that comprise duplicate records is the most important part of the duplicate removal process.
Removing duplicate Records in TSQL is likely to be a unique situation every time but there are enough consistent characteristics to the task that we can standardize some of it. I certainly would not want a one-button-click solution because that would have too narrow a view of what a duplicate is. Defining a duplicate is something for administrators to do because they know their data better than anyone else. Ask a director, a manager and a user what a duplicate record is and you will likely get three different answers. Sure, each will tell you when records appear as duplicates in reports and such, but the combination of fields that make up a duplicate is something that should be examined closely in every situation. Other than the standard of backing up a table, identifying the fields that comprise duplicate records is the most important part of the duplicate removal process.
That being said, I have developed a semi-universal TSQL process that I use to identify and remove duplicates. I use row_number, dense_rank and partition.
You probably already know how row_number creates a number incremented by one for each row. Adding partition to row_number groups the results such that each new group begins a new pecking number within the set. Dense_Rank creates the same incremented number for each item in a set. Using both of these will enable us to:
- Identify entire sets/groups of records where data in given fields are the same
- Allow us to select/update/delete any subset within each set/group
- Any multiples of records greater than one (just the duplicates – 2nd, 3rd,4th etc.)
- Any specified item in a set/group (1st, 2nd, 3rd etc.)
/* Proof of concept for removing duplicates
Intended use:
1.) Updating multiples of identical records.
2.) Removing second thru n count of duplicates.
Author: Tim Bartel 2015.09.22
*/
-- Create simple table of employee records
create table employees (
recordID int IDENTITY(1,1) NOT NULL,
nameFirst varchar(50),
nameLast varchar(100),
salutation varchar(10),
employeeNumber int,
hireDate date,
exitDate date
)
-- Insert some records, including duplicates of employee number
insert into employees (nameFirst, nameLast, salutation, employeeNumber, hireDate, exitDate)
values ('April', 'Showers', 'Ms', 1001, '2010-01-31', null),
('May', 'Flowers', 'Ms', 1002, '2010-05-01', null),
('Jack', 'Jumping', 'Dr', 1003, '2011-06-11', null),
('Sal', 'Manilla', 'Mr', 1004, '2012-12-14', null),
('Al', 'Bondegas', 'Mr', 1005, '2013-09-15', null),
('Trip', 'Youup', 'Sr', 1006, '2013-09-15', null),
('Trip', 'Youup', 'Jr', 1007, '2014-07-10', '2014-08-10'),
('Trip', 'Youup', 'Jr', 1007, '2015-02-24', null),
('Trip', 'Youup', 'Jr', 1007, '2015-02-24', null),
('Trip', 'Youup', 'Jr', 1007, '2015-02-24', null),
('Mia', 'Culpa', 'Mrs', 1008, '2011-09-01', null),
('Ben', 'Stumped', 'Mr', 1009, '2014-08-10', '2014-09-10'),
('Ben', 'Stumped', '', 1009, '2015-03-24', null),
('Ben', 'Stumped', '', 1009, '2015-03-24', null),
('Ben', 'Stumped', 'Mr', 1009, '2015-03-24', null),
('Ben', 'Stumped', '', 1009, '2015-03-24', null)
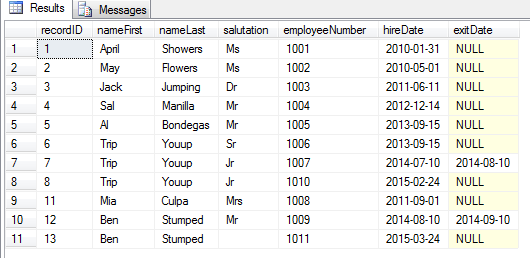
Have a look at the records. Note that Trip Youup and Ben Stumped, are both previous employees who have returned and have been given the same employeeNumber as thier first time as employees. These are easy to spot and query by the exitDate in a small rescord set like this one (records 9,10 and 14,15,16 are true duplicates which need to be deleted, while records 8 and 13 need a new employeeNumber). Note that the first instance of Trip Youup with employeeNumber 1006 is a different Trip Youup than those with employee number 1007. 1006 is Trip Youup Senior, and 1007 is Trip Youup Junior. So employeeNumber is a determining factor.
select * from employees
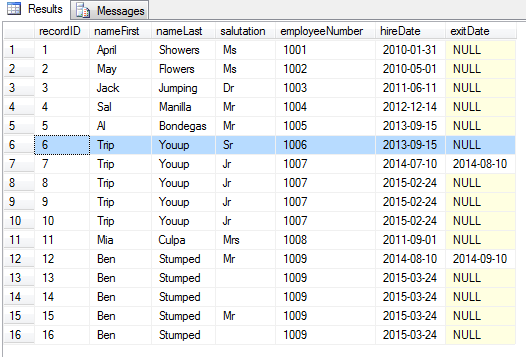
Check for duplicates, create rownum for ordering and dense_rank for grouping.
ORDERING:
* rownum is a sequential count that resarts with 1 at the first new instance of records that meet the criteria in the partiton by clause.
** The end result is an ascending count of duplicate records which can be used for ordering of duplicate records, and selecting any multiple by count value
GROUPING:
* Desnse_Rank is a sequential count that repeats with each duplicate record which meets the criteria in the order by clause.
** The end result is a unique number that can be used to group identical records of the specified criteria.
select * from ( select row_number() over(partition by employeeNumber, nameFirst, nameLast order by employeeNumber) as rownum, DENSE_RANK() over(order by employeeNumber) as rank, recordID, nameFirst, nameLast, employeeNumber, hireDate, exitDate from employees ) e -- all 16 records where rownum >1 -- 7 records returned (One set of three [rank 7], and one set of four [rank 9])
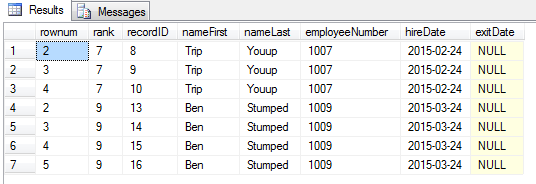
We need to do the following:
- Keep the first instance of the employeeNumber unchanged
- Create a new employeeNumber for the second instance (the third + records can be changed too, it doesn’t matter because we are going to delete them)
- Delete all remaining multiples
- Make the script scalable for higher volume of records
-- Create a temporary table that contains only the multiples records 8,9,10 and 13,14,15,16), not the first instances (records 7 and 12). -- Use dense_rank in the outer select to get the value which we will use to increment the employee number (Addend) select DENSE_RANK() over(order by rank) as 'Addend', * into #employees_temp from ( select row_number() over(partition by employeeNumber, nameFirst, nameLast order by employeeNumber) as rownum, DENSE_RANK() over(order by employeeNumber) as rank, recordID, nameFirst, nameLast, employeeNumber, hireDate, exitDate from employees ) e where rownum >1
How to select all instances of duplicates – including the first one
select * from employees where employeeNumber in (select employeeNumber from #employees_temp where rownum >1) -- the full compliment of 9 rows
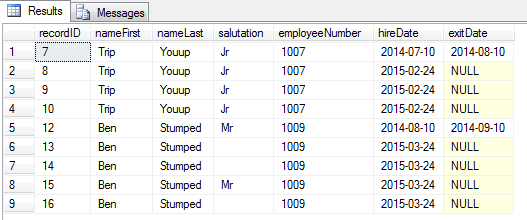
How to select only the non-primary instances of the duplicates (counts 2 thru n)
select * from employees where recordID in (select recordID from #employees_temp where rownum >1) -- just the 7 duplicates
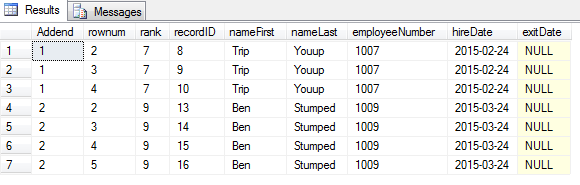
Check calculation for changing the employeeNumber to the next highest number that is not in use
Note:
Augend – mathematical term for the first of the two numbers being added. Addend – mathematical term for the second of two numbers being added.
declare @newEmpNum int select @newEmpNum = (select max(employeeNumber) from employees) select e.recordID, e.employeeNumber, rank, @newEmpNum ' Augend',Addend, @newEmpNum + Addend 'Sum' from #employees_temp et inner join employees e on et.recordID=e.recordID
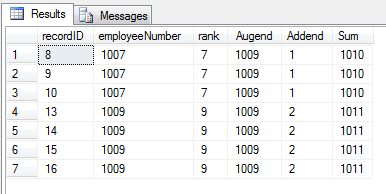
Convert select to an Update: Records 8,9,10,13,14,15 and 16 will be updated
declare @newEmpNum int select @newEmpNum = (select max(employeeNumber) from employees) UPDATE e set e.employeeNumber=@newEmpNum + Addend from #employees_temp et inner join employees e on et.recordID=e.recordID -- (7 row(s) affected)
How to select duplicates from temp table
select * from #employees_temp where rownum > 2 -- 5 records
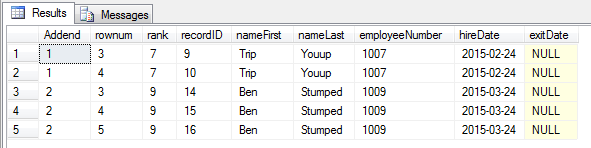
Delete duplicates from employee table based on recordID (unique key) of duplicates in temp table)
delete from employees where recordID in (select recordID from #employees_temp where rownum > 2) -- (5 row(s) affected)
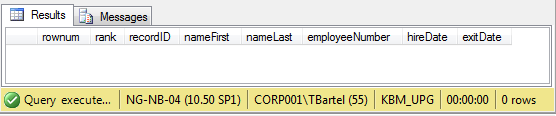
Records 9,10,14,15 and 16 are now deleted.
select * from employees
Check for duplicates
select * from ( select row_number() over(partition by employeeNumber, nameFirst, nameLast order by employeeNumber) as rownum, DENSE_RANK() over(order by employeeNumber) as rank, recordID, nameFirst, nameLast, employeeNumber, hireDate, exitDate from employees ) e where rownum >1 -- zero records returned
Let me know if you found this useful.
Leave a Reply